- Published on
Jacobi vs. Gauss Seidel - Notes for Dummies
- Authors

- Name
- Bojun Feng
Summary:
Intro
In numerical analysis, Jacobi Iteration and the Gauss Seidel method are classic examples of iterative methods. However, since most classes focus mainly on deriving the equations, it is easy for the underlying intuition to be buried under a mountain of mathematical symbols and pseudocode. After reading the explanations online, I felt like I understood each step of the derivation, but confused about the more practical side of things: How are these two algorithms different? What are the pros and cons of each? This post contains some of my notes.
Also, shoutout to Dillon Grannis for clarifying a lot of the mathematical concepts!
That's enough context. Let's get started.
The Coding Explanation
Essentially, we have a system , where is a matrix and are vectors. We know values of matrix and vector but not vector :
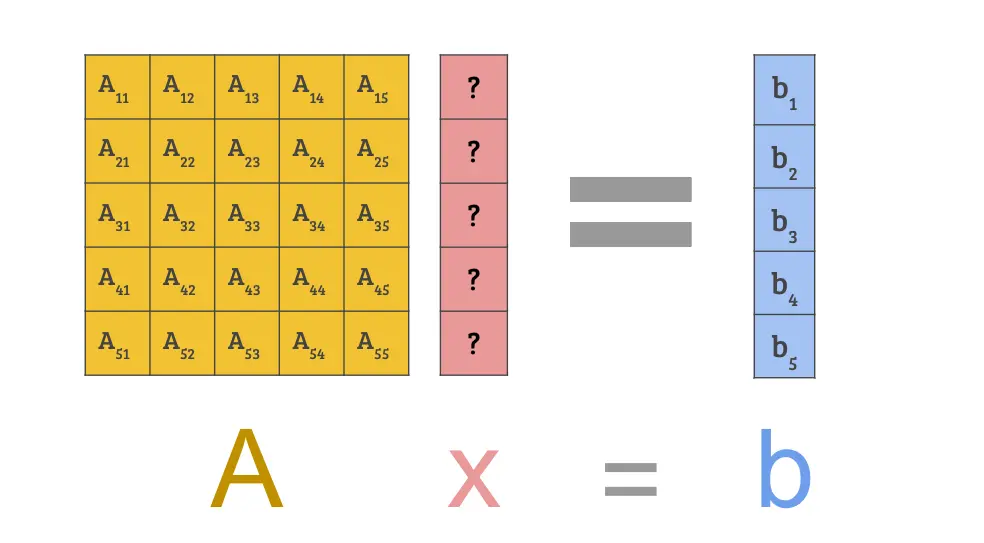
Under this condidion, here is a crash course on the two methods:
- If follows certain conditions, the Jacobi Iteration can find a better approximation of given , , and a current approximation .
- If follows slightly more conditions, the Gauss Seidel method can do the same as Jacobi, but with better performance.
- Practically, we start from some approximation and run one of the two methods many times until we are satisfied with the result.
- Usually, we denote the guess to keep track of the iterations. In this language, each mathod takes in , , and produces as a better guess.
What's the Difference?
Both methods provide a formula to compute the term of , which we call , using the subscript to indicate the elements within the vector.
In the two methods, the formula (denoted "f" in the image) is actually the exact same, the only difference being the order we update the values.
In Jacobi Iteration we compute the entire from :
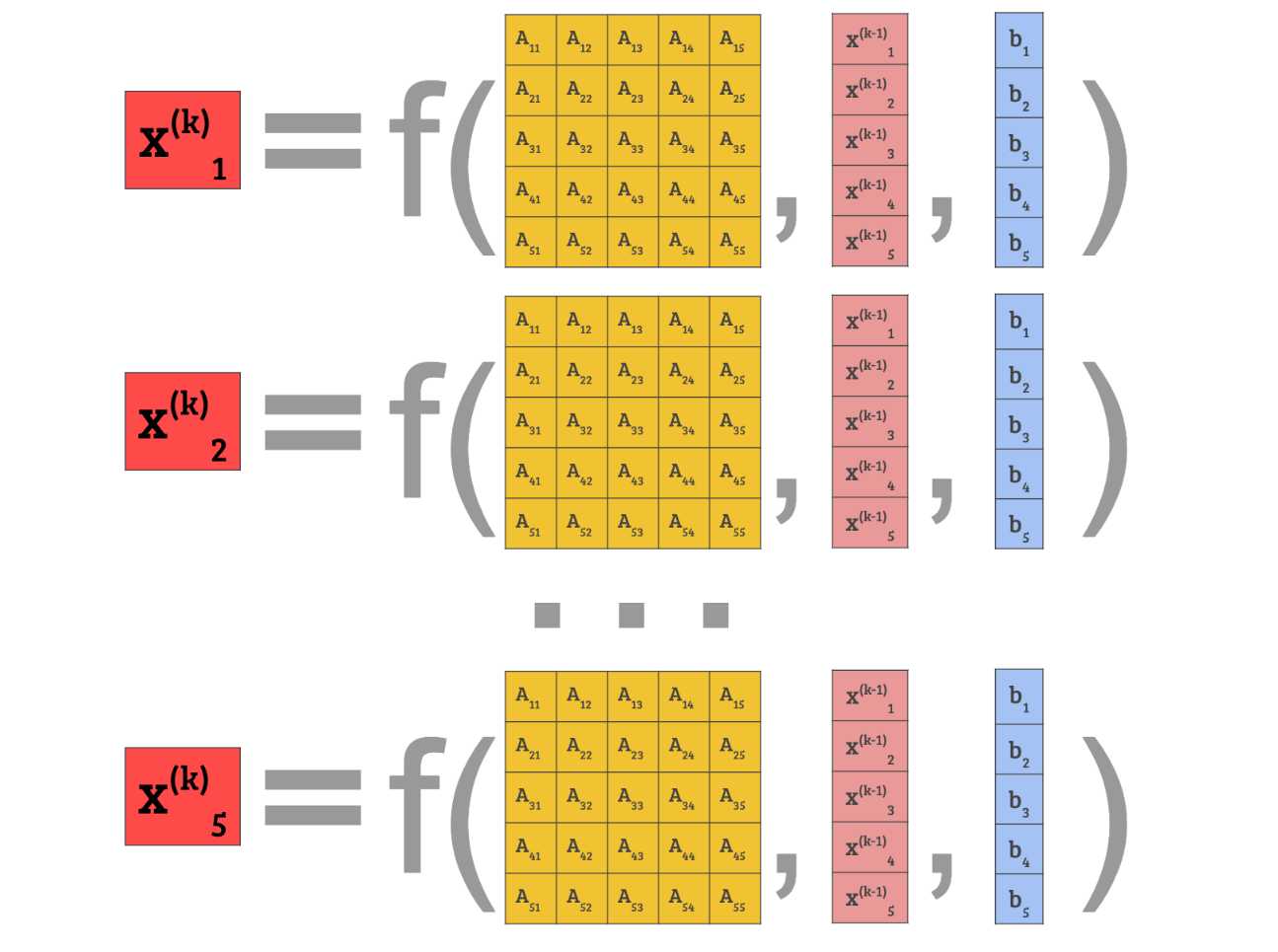
Then we throw away the vector as a whole, replacing it with the new guess .
In Gauss Seidel method, however, we throw away right after computing .
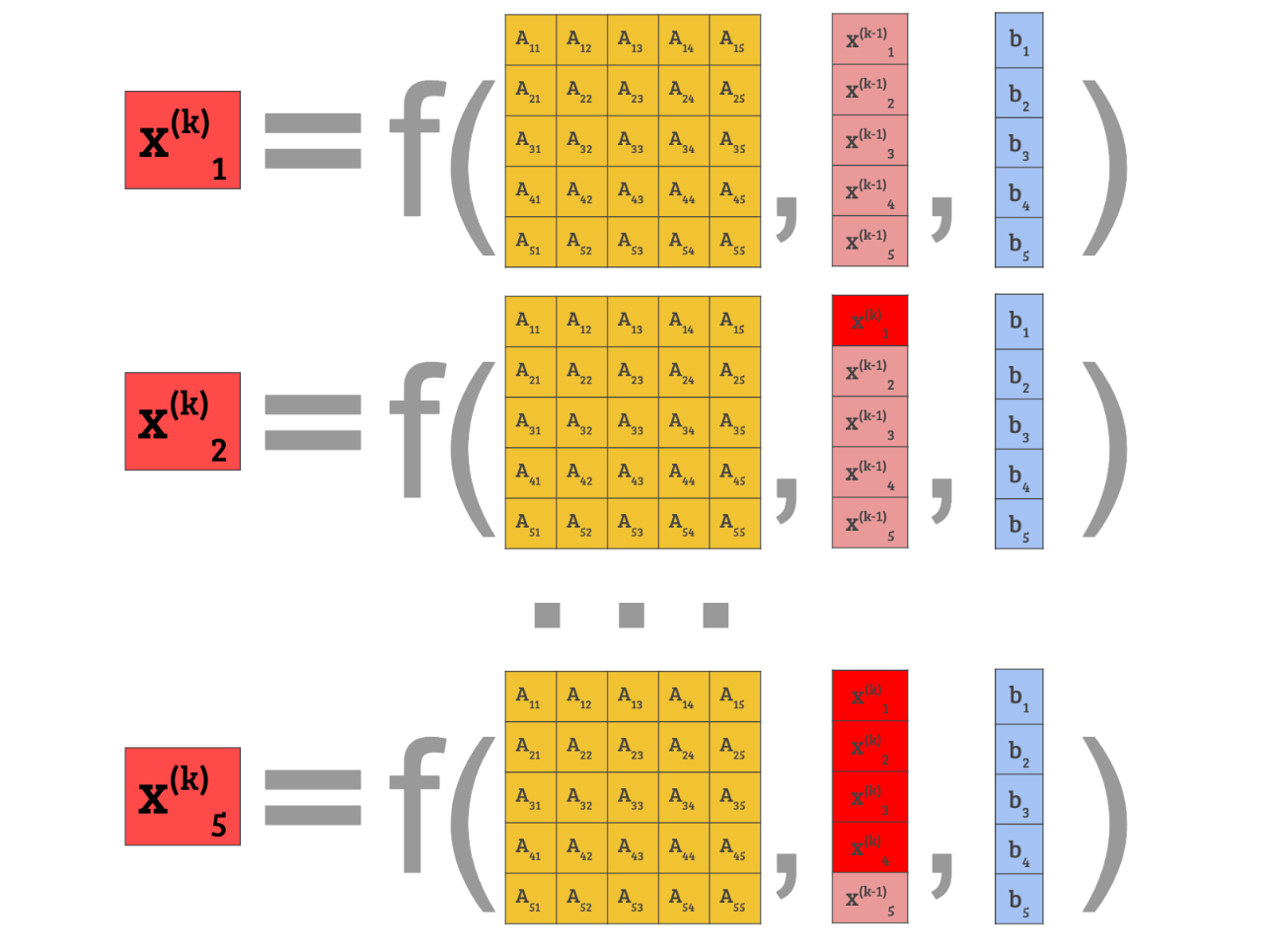
After finishing the computation, we just need to replace the last term before starting the new iteration.
Which is Better?
Pros of Jacobi Over Gauss Siedel:
- Jacobi has less strict requirements than Gauss Seidel, so certain classes of questions can only be computed with Jacobi iteration.
- Jacobi is very good for distributed programming, since for different values of can be computed simutaneously on different computers.
Pros of Gauss Siedel Over Jacobi:
- Gauss Siedel generally has better performance over Jacobi, since it uses updated values immediately and don't have to wait for the entire vector to finish.
- Gauss Siedel can save a lot of space, since we don't need to keep track of both and at the same time. Gauss Siedel only need one vector of memory, while Jacobi needs two.
The Mathy Explanation
To begin with, this is NOT a rigorous proof! We will be making many assumptions throughout this section without diving into the details, and a math textbook would be a much better source of information if you are looking for Lemmas and Theorems.
Instead, this section contains a quick rundown of the intuiton behind these algorithms, with some equations sprinkled throughout.
Linear Algebra 101: How to Approximate
Let's start simple. Given any invertible matrix :
Similarly. Given any invertible matrix :
That's a good warmup. Now we can look at something more interesting. Let's replace with a sum of powers of and see what we get:
Note how the terms cancel out with each other! The same rule holds if we add more powers of . Since all consecutive terms cancel out except for the first and the last, we have:
Or, if we want to write it formally and save some space:
We now make an assumption about : Suppose becomes smaller and smaller as its power goes up. In other words, gets smaller as gets bigger. gets super close to zero as gets super large.
More formally in terms of limit, we can write it as:
We can make a very similar claim regarding :
Now we can plug this limit into the above equation, where the right hand side is , which gets super close to just as gets super large.
More formally in terms of limit, we can write it as:
Recall that we have seen another equation with on the right hand side:
Putting the pieces together, we have:
And, if is large enough:
As long as is a nice matrix, in the sense that exists and gets smaller as gets bigger, we can use the above logic to approximate with sums of .
Approximate, but in Linear Systems
Now that we know how to approximate things, we can try to apply what we've learned to a linear system. Consider the following (familiar) scenario, where we know values of matrix and vector but not vector :
Let's try to reframe it into something more familiar.
Define a matrix so we have :
That looks familiar! Rewrite the above equation into a easy to read format, we essentially have:
The more terms of we have, the more accurate the result would be!
One step further: Jacobi and Gauss Seidel
Finally, we can get to the meat: What is exactly going on in Jacobi and Gauss Seidel?
They essentially does what we did above, but took it one step further by breaking the matrix into two parts:
is the "good" matrix and is the "bad" matrix. Both matrices are of the same size, but there is a key difference: Only the good matrix is guaranteed to be easily invertible. The bad matrix can be either hard or impossible to invert.
As a result, we are okay with computing but not .
After we break down, let's look at the linear system again:
Since we are okay with calculating , we can multiply both sides with it:
This is looking a bit more familiar, but not quite enough.
Let's rewrite it some more. Define and , we plug them into the equation:
Applying the formula from the last section:
Voila! We have our approximation. Or, expanding the formula into and :
Essentially, this is what Jacobi and Gauss Seidel are doing, although they broke down differently:
- Jacobi chose to be just the diagonal, and is everything but the diagonal.
- Gauss Seidel chose to be both the diagonal and everything below the diagonal, and is everything above the diagonal.
Tying the Math to the Code
The above explanation still begs a question: How do we compute that, exactly?
Both Jacobi and Gauss Seidel are iterative methods, so they perform the computation in iterations. Every new iteration makes an improvement on top of the previous one and produces a more reliable result.
The intuition is for us to add one term of in every iteration:
However, we don't want to recompute everything on each step since that takes up a lot of space in the computer. How can we compute the iteration while minimizing the cost?
Ideally, we can just use the values of , , and to perform the computation. The key is in the following equation:
After shuffling the terms, we have:
And that is it! Of course, when we are applying Jacobi or Gauss Seidel, we are operating with the good and the bad matrix under the hood:
This can also be written as:
This would be the general form we need to perform the computation.
The exact formula of Jacobi and Gauss Seidel are then derived from writing each term down and expanding them, which is some painstacking calculation that I am not going to type up in latex. If you trust me, here are the formulas for solving .
Jacobi:
Gauss Seidel:
In Gauss Seidel, we skipped quite a bit of computation by using the already computed terms in instead of revisiting all the terms in .
In coding practice, the similarity in formulas makes Gauss Seidel almost the same as Jacobi, the only difference being we are throwing away immediately after is computed in Gauss Seidel, while in Jacobi we wait until the entire vector is computed before throwing away all together.